用 Python-Flask 打造 API - Postgres 本地篇
前言
今天這篇我要來記錄如何在 Flask API 中串接並使用 Postgres
我在上一篇中提到在 Heroku 上用 SQLite 作為資料庫的缺點,以及 Heroku 推薦使用 Postgres
因此我去研究了如何做到這一點
過程遇到很多 error 真的很崩潰,也沒有把遇到的每個問題都記錄下來有點可惜
現在就憑印象,能寫多少就多少吧
這邊我會把 postgres 操作分成 local 跟 remote
先從 local 開始吧
安裝 Postgres
PostgreSQL 是一款蠻有名的關係資料庫
有時候縮寫成 Postgres
那我們到這裡下載不同作業系統對應的安裝軟體
那我用的是 Windows,所以這裡就用 windows 來舉例
安裝時注意一件事
我們要另外自己手動安裝 pgAdmin
所以記得把這個 pgAdmin4 的選項取消,不要選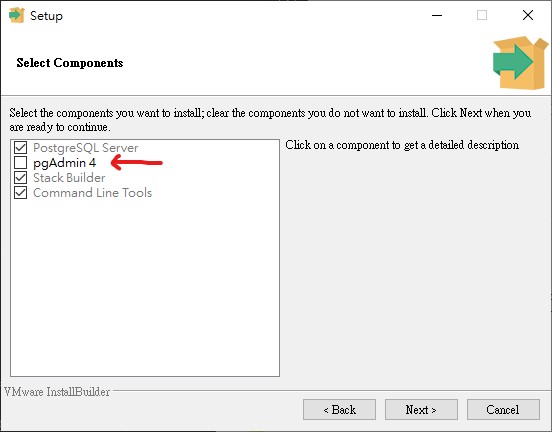
接下來他會請你指定安裝路徑,super 使用者的密碼,預設 port,時區(選default就好)
再來要到這裡安裝 pgAdmin
安裝過程很單純,一直下一步到安裝就好,不會有什麼問題
完成後打開它
到這邊安裝就差不多了
在本地串接 API 和 Postgres
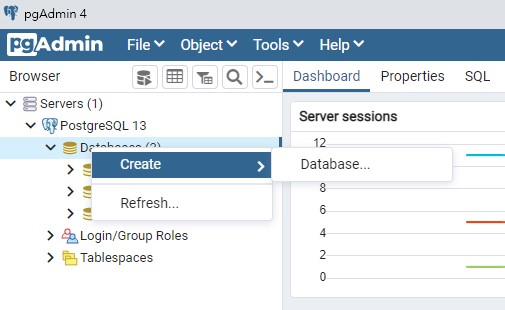
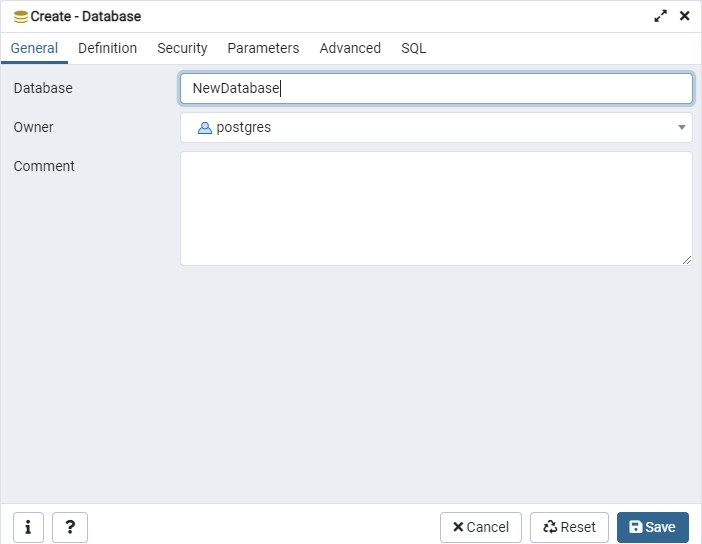
點擊此處建立資料庫,取名
(以後面的例子而言我是取 issuedata,不是圖裡的 NewDatabase)
接下來回到程式端
前幾篇文章的程式碼都是 for 教學用的
但我現在做了正式版,是將來要應用在 TAN 網站的版本
為了不造成混淆我先把連接資料庫前的正式版程式碼貼上來~
1 | from flask import Flask, Request |
要連接本地 postgres 資料庫,我需要加上:
1 | app.config["SQLALCHEMY_DATABASE_URI"] = 'postgresql://postgres:et0997@localhost/issuedata' |
我們先來看第一行
app.config["SQLALCHEMY_DATABASE_URI"] = 'postgresql://postgres:et0997@localhost/issuedata'
這段 uri 的格式是 postgresql://<username>:<user_password>@<port>/<database_name>
- username: PostgreSQL 的使用者。由於我沒有另外新建使用者,所以就用 super user 也就是
postgres就可以了 - user_password: user 密碼。你在安裝 postgres 的時候不是有設定過一次密碼嗎? 就是那個(user 選 postgres 的話啦)
- port: 連接端口。由於我們是在本地測試,所以填
localhost就好 - database_name: 你剛剛用 pgAdmin 建立的那個資料庫名稱
總之這行是在告訴 Flask_SQLAlchemy 應該連接什麼資料庫,要怎麼找到它
最底部的 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
是為了避免跳出以下 warning
1 | warnings.warn('SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead |
就我的理解
這是 Flask_SQLAlchemy 造成的小問題
它的意思是
由於 Flask_SQLAlchemy 是 SQLAlchemy 的一個包裝(類似升級版)
本質上還是 SQLAlchemy 在運作
而 Flask_SQLAlchemy 有自己的一套 event notification system
(不知道怎麼翻比較好,直接用原文)
所以它必須隨時監聽 SQLAlchemy 的任何修改(如’SQLALCHEMY_TRACK_MODIFICATIONS’字面上的意思)
這可能會造成性能瓶頸
設為 False 避免這個問題
至此就設定好本地連接了
建立 local DB 的 table 和 資料
接著打開 python shell
1 | from app import db, Issue # 從 app.py 引入 db 和 Issue 模組 |
完成後打開 pgAdmin
從以下路徑找到名為 issuedata 的 table
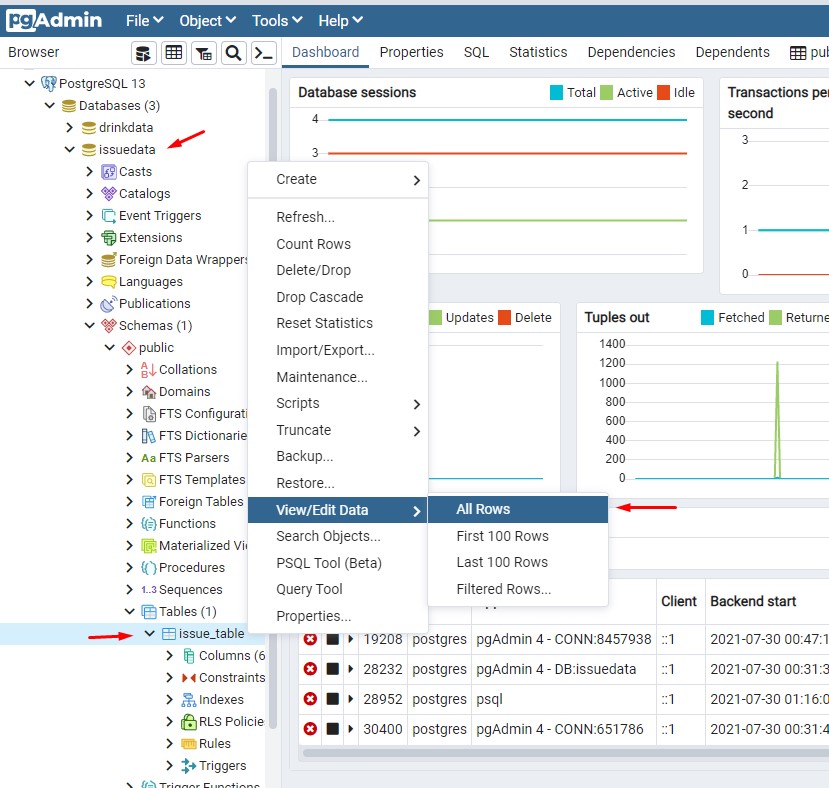
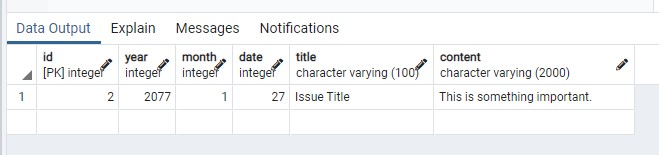
耶! 看到資料了
結語
剛剛的安裝過程都只是在自己的電腦上存取資料而已
但最終我們要把 API 放在網路上呀
到時要怎麼用 Postgres 呢?
我覺得 部落格好像不太適合寫太長
遠端的部分就留到下一篇吧!